本文共 859 字,大约阅读时间需要 2 分钟。
加州大学伯克利分校的研究人员,近日在著名预印本网站 arXive 上,发布了最新的图像迁移成果:人体姿势和舞蹈动作迁移。旨在把专业舞蹈演员的动作迁移到不会跳舞的人身上,算法输出流畅,还原度极高。小编在感叹黑科技真厉害的同时,不禁为该算法的用途捏一把汗。因为就在不久前的 DeepFakes 深度换脸算法,还被人拿来将明星的脸换到成人影片上。

这篇文章的名字叫做:Everybody Dance Now, 是加州大学伯克利分校的研究人员:Caroline Chan, Shiry Ginosar, TingHui Zhou, Alexei A. Efros 在8月22日提交到 arXiv上的。文章中提出了一个简单动作迁移的方法:首先选择一支单人跳舞视频作为源视频,将其中的动作转换到目标视频中。 只需要几分钟,在另一个目标视频上的目标人员(完全不会跳舞的人)就会呈现同样的动作。
文章将动作姿态迁移看作是每一帧上图像到图像的转换,同时保证时间和空间的流畅。用动作探测器作为源视频和目标视频中间的表示,学习了一组从舞者动作画面到目标物体的映射,并且对这些数据进行调整,让它与视频完美融合,同时还加上了真实的人脸合成。通过这一框架,他们让很多未经训练的人跳出了芭蕾和街舞。
文章设计了能体现动作的中间表现形式:左图的火柴人。

从目标视频中,作者用动作识别器为每一帧制作了(火柴人, 目标人物图像)的组合。有了这样相关的数据,作者就能用监督方法学习火柴人和目标人物之间图像到图像的转换模型了。之后,为了将源视频的动作迁移到目标视频中,作者把火柴人输入到经过训练的模型后,得到和源视频中人物相同的目标动作。
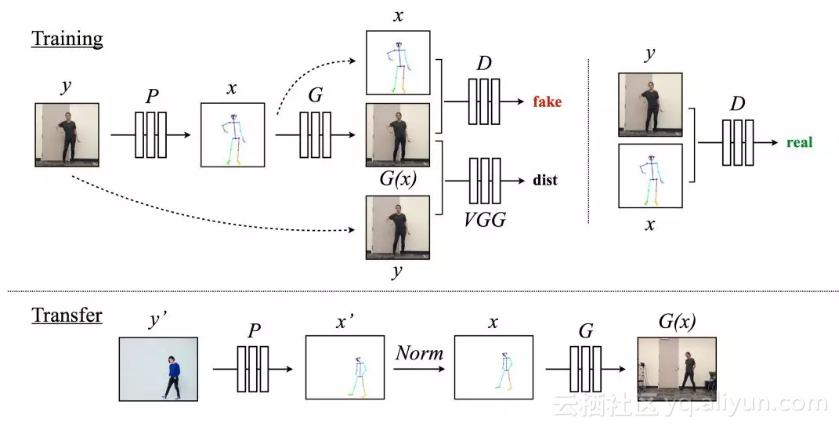
另外,为了提高生成的质量,作者添加了两个元素:
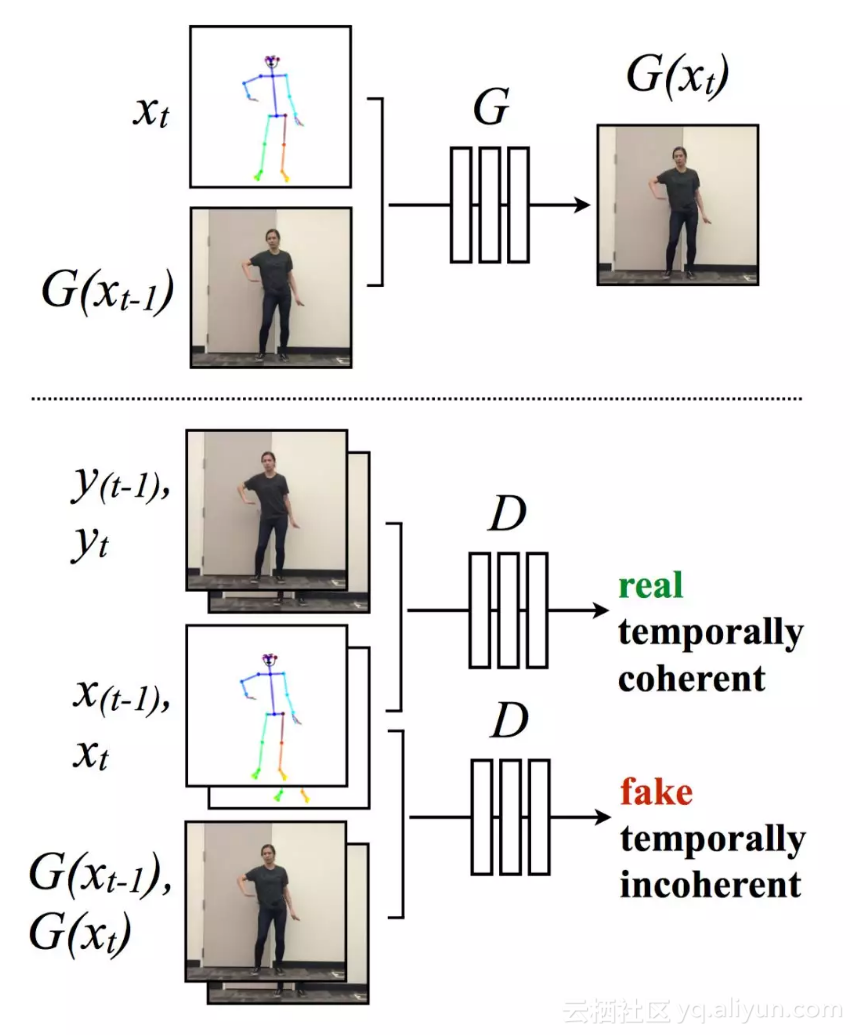
1. 为了使生成的模型更连贯,作者会根据上一帧对目前的帧进行预测;
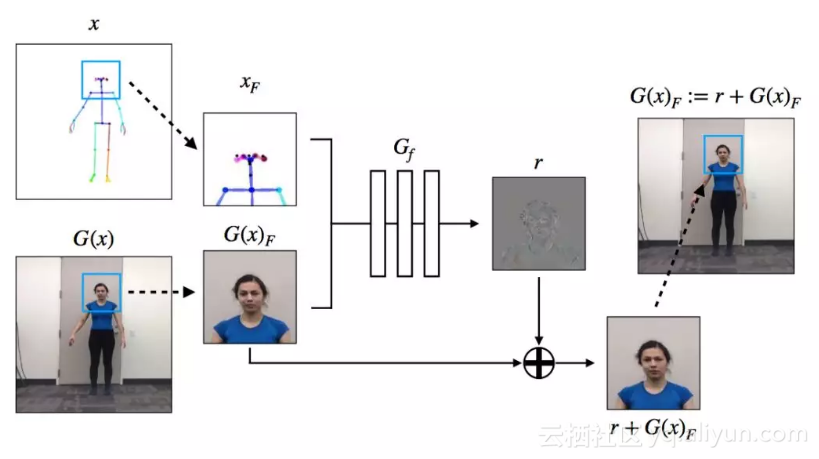
2. 为了提高生成人脸的真实性,作者加入了经过训练的GAN来生成目标人物的脸部。
 原文发布时间为:2018-08-30本文作者:huaiwen本文来自云栖社区合作伙伴“ ”,了解相关信息可以关注“ ”。
原文发布时间为:2018-08-30本文作者:huaiwen本文来自云栖社区合作伙伴“ ”,了解相关信息可以关注“ ”。 转载地址:http://azfnx.baihongyu.com/